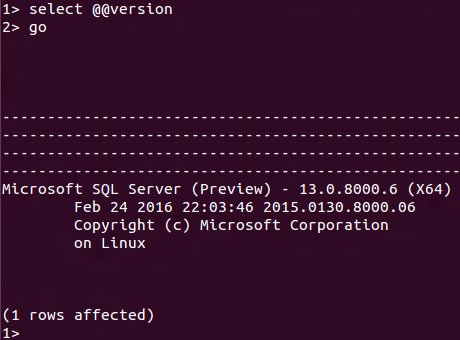
Sim, SQL Server rodando em Linux.
Um
assunto que pegou até MVPs de Data Plataform desprevenidos, pois muitos não
tinham ideia de que isso poderia acontecer. E mesmo com inúmera incógnitas, não
posso deixar passar em branco o assunto sem um post.
Eu estou
ANIMADO com o anúncio e vou expor meus motivos, porém primeiro vou listar o que
nós não sabemos (nem mesmo os MVPs de SQL
Server):
- Quais serão as
funcionalidades suportas pelo produto. Será todo o core da engine
relacional? Integration Services?
- Hekaton, Columnstore, e
outras funcionalidades que estão brilhando, estarão incluídas?
- Teremos Enterprise, Standard
e todas as outras edições?
- Os releases serão
sincronizados ou podemos esperar uma defasagem de funcionalidade entre SQL
Server do Windows e Linux?
- Como será o SQL Server Agent?
Controlaremos nossos jobs pela cron?
- Quais serão as distribuições
de Linux suportadas? Suse?
- Suportaremos quais file
systems? Ext3, ext4, reiserFS, XFS?
- Quais serão as ferramentas?
Vamos ter o SSMS on Linux? Visual Code será suficiente? Vamos usar IDEs
como Eclipse?
- Haverá interoperabilidade
entre plataformas? Isto é, um backup de um banco no Linux pode ser
restaurado em um SQL Server rodando no Windows?
- Teremos 100% de
compatibilidade no T-SQL?
- Como fica integração com o
CLR?
- Diferente do Windows, onde o
SQL Server não alterada nada no kernel do SO, será que teremos compilações
de kernel específicas para o SQL Server?
- Vão abrir o código fonte do
SQL Server? (Aqui eu aposto contra…)
O que nós
sabemos:
- O produto está em preview,
então não é vaporware.
- General Availability está
programada para meados de 2017, isto é, mais de um ano para frente.
- Primeiramente devemos ver o
SQL Server com Red Hat e Ubuntu.
Ficou
claro que a listagem de dúvidas é muito maior que a de certezas, o que não
deixa o assunto menos interessante.
O que é
mais legal e me deixa motivado, é que teremos a possibilidade de acompanhar o
SQL Server em uma nova jornada, podendo analisar e aprender com os acertos e
erros da Microsoft e seus desenvolvedores. Então elucubro sobre alguns pontos…
- Fica
evidente mesmo para os mais míopes, o que já sabemos: “Data is the
core asset now.”
Mr. Nadella said.
- Linux é um grande sistema
operacional e com um market share significativo. Estar presente nele
representa uma oportunidade para a Microsoft e, claro, para todos os DBAs
SQL Server.
- O que não
significa que o SQL Server irá se comportar melhor.
- As empresas poderão optar por
ter um excelente banco de dados (veja prosa abaixo) mesmo que esteja com
seus servidores rodando Linux.
- O poder de
escolha é importante para o negócio, e caso a Microsoft garanta
compatibilidade do T-SQL e boa integração entre plataformas, a migração
Windows -> Linux pode ser facilitada.
- Será possível fazer
comparações efetivas de desempenho entre o SQL Server e outras engines
rodando com mesmo sistema operacional e hardware.
- Só isso já
vale o ingresso, a comparação efetiva de engines ou funcionalidades
específicas, sem ficar com discursinho de que se fosse no Linux o
resultado seria outro.
- Muitos DBAs SQL Server vão
ter que aprender Linux e isso fará com que eles estudem e comparem as
plataformas. Saber as diferenças e como explorar os pontos fortes de cada
sistema operacional vai te deixar um melhor profissional.
- O que não
significa que será melhor ou mais fácil… Por exemplo: deixe de agendar
seus jobs com o SQL Server Agent e passe a usar a cron. Ou melhor, tente
criar no Linux um monitor de desempenho como faz no Perfmon, cruzando
dados de sistema operacional (memória, processos, processadores, I/O,
rede), com contadores do SQL Server (access methods, buffer manager, SQL
Statistics).
- Poderemos observar a
qualidade do código produzido pela Microsoft para suportar diferentes
sistemas operacionais. Será que ela fará melhor ou vou encontrar listas
gigantescas de correções como eu vejo no DB2 LUW?
Prosa SQL Server, Oracle, DB2, PostgreSQL, …
Relembrando:
Essa prosa vem de um geek que estudou por muito tempo o SQL Server, administrou
por quase 2 anos e meio o DB2 LUW com Suse Linux, foi massacrado com
informações sobre o Oracle no treinamento do Portilho e agora eventualmente
investe uns minutinhos lendo coisas a sobre o PostgreSQL. Isto é, com certeza
escrevo muita besteira…
Hoje
temos o DB2 e Oracle com mais funcionalidades que o SQL Server, algumas
sensacionais que eu gostaria de ver no SQL Server, além da possibilidade de
fazer ajustes finos em diversas configurações (mesmo que quase ninguém o faça).
Já no SQL Server eu vejo uma engine mais concisa e muito eficiente, e um
produto que está se adaptando mais rápido às inovações/pesquisas de banco de
dados (talvez por não ter que manter diferentes SOs), o que pode ser um
diferencial nos próximos anos.
Vejo na
nova direção da Microsoft, abraçando o Linux e open source, a possibilidade de
muitos de nós sair de um casulo dentro de uma plataforma (como eu vivi por
muitos anos!!) e até de abraçarmos modelos diferentes. Quem sabe no futuro
veremos menos gastos com uma cadeia gigantesca de vendedores, minimizando o
custo do licenciamento, melhorando o serviço de suporte e focando no que
realmente importa: a qualidade dos produtos e resolver os problemas dos
clientes. Seria muito bom ter que parar de desmentir histórias que alguns
vendedores contam…
Já disse
isso para vários clientes (inclusive um bem recente) que para a grande maioria
dos ambientes transacionais, não importa se o seu banco é Oracle, SQL Server,
DB2 ou PostgreSQL (que tem recebido muitos elogios e acho que merece ser
acompanhado de perto), o que importa muito mais é como fazemos a adoção da tecnologia e se estamos utilizando-a de forma
efetiva.
Por fim,
espero sinceramente que o maior benefício seja produzirmos comparações de
qualidade, discussões inteligentes e que isso traga maior maturidade para TODOS
os profissionais que trabalham com banco de dados. A aproximação da Microsoft
com o Linux deve fazer com que DBAs SQL Server se aproximem de outras engines e
também trazer DBAs Oracle/DB2/PostgreSQL para explorar um pouco do SQL Server,
quebrando mitos e preconceitos.
Quero
poder discutir e testar se o completely fair scheduler (https://en.wikipedia.org/wiki/Completely_Fair_Scheduler) é realmente ruim para máquinas com banco de dados que não adotam
um modelo cooperativo de escalonamento (como eu acredito ser). Quero poder
falar sobre configurações do SO (ex.: swapiness, huge pages), ou se a
implementação do Vectored I/O (https://en.wikipedia.org/wiki/Vectored_I/O) no Linux realmente não é a ideal (como eu
já soube), tudo isso sem esbarrar na barreira de minha versus sua plataforma de
banco de dados ou sistema operacional.
Mas tem
uma coisa que continuará igual: os manés xiitas
sempre existirão.
Isso não
mudará, infelizmente teremos manés em todas as plataformas. Vou continuar
observando calado um DBA de outro SGBDR dizendo que eu, DBA SQL Server, não
sei administrar banco de dados sem mouse, notando em seguida que o infeliz não
tem a menor ideia do funcionamento de um banco de dados (pela minha observação, os xiitas tendem a ser os mais leigos). E mesmo sabendo que em
dois ou três meses estudando o SGBDR muitos profissionais seriam melhores do
que ele, continuarei calado. Para esses xiitas, que por desconhecimento de
outra tecnologia, continuam a arrotar besteiras colossais e se sentindo
maiorais, meu total desprezo.
Estamos
vivendo tempos excitantes no mundo dos bancos de dados e essa mudança dentro da
Microsoft e com o SQL Server eu quero assistir de camarote. Pode ser que
ninguém adote o "novo" produto, pode ser que o desenvolvimento falhe
espetacularmente e venha com muitos bugs ou péssimo desempenho, ou que as
ferramentas não sejam tão interessantes como as que temos hoje. Ou pode ser que
o SQLOS ofereça uma abstração fantástica e o produto se adapte muito bem em um
novo SO, deixando muita gente de queixo caído. Seja qual for o resultado desse
movimento, com certeza ele trará muito aprendizado.
De
quebra, quem sabe um dia não teremos um treinamento Mastering SQL Server on
Linux na Sr. Nimbus, irmão do já conhecido Mastering
http://www.srnimbus.com.br/sql23/.
Quer
acompanhar de perto também? Se cadastre no preview e acompanhe o evento Data
Driven que acontecerá no dia 10 de março, onde provavelmente vão falar sobre o
assunto.
Se
estiver com tempo e quiser analisar por outras fontes como está sendo recebida
a notícia, alguns links:
Ah, Kevin
Farlee colocou essa imagem no twitter… Esse não acredito ser fake, como muitos outros que já vi. :-)
======================
UPDATE ======================
Seria
legal também ouvir comentários de profissionais Oracle, DB2, Postgres… E aí,
acham que isso vai vingar? Tem curiosidade com o que está por vir ou não vai
fazer a menor diferença no mercado?
Abraços
Luciano Caixeta Moreira - {Luti}
luciano.moreira@srnimbus.com.br
www.twitter.com/luticm
www.srnimbus.com.br