Sempre acreditei no potencial e benefícios que a computação na nuvem pode trazer para as empresas, a economia de escala é fantástica, a facilidade pode apoiar equipes multidisciplinares e suportar grandes ideias de pequenos, e não é a toa que em 2009 fundamos a Nimbus e nosso logo é uma bela nuvenzinha.
Porém como esperado o ciclo de adoção aqui no Brasil é mais lento que nos EUA, e outras apostas ainda não aconteceram: eu torcia para aparecer um datacenter da Microsoft por aqui, o que não aconteceu até agora e acredito, facilitaria demais as coisas. Mas quando falamos em cloud computing não nos podemos restringir só a Microsoft, hoje temos muitos players brigando forte nessa competição, como a Amazon, o que sempre é muito saudável para o consumidor final.
Falando em serviço temos: software as a services (SaaS), plataform as a service (SaaS), infrastructure as a services (IaaS), entre outras tantas letrinhas mais. Sendo fora do escopo deste post o detalhamento do que é cada um (já existem muitos artigos cobrindo o assunto) e a discussão sobre o SQL Azure – ou SQL Databases - (onde você consome o SQL Server como um serviço), uma frente que recentemente ganhou mais atenção do pessoal de SQL Server foi o IaaS, onde a infra-estrutura (hardware) é oferecida para nós montarmos nossas máquinas virtuais e colocarmos o SO, SQL Server ou qualquer outro serviço.
IaaS + SQL Server
A pergunta do momento é: vale a pena colocar o SQL Server rodando na nuvem em uma infra-estrutura disponibilizada pela Microsoft ou Amazon? Obviamente que a resposta para essa pergunta é um grande DEPENDE, o potencial é bem promissor, porém existem muitos pontos que precisam ser analisados com cuidado, não é só levar a coisa “as it is” para a nuvem que você está numa boa.
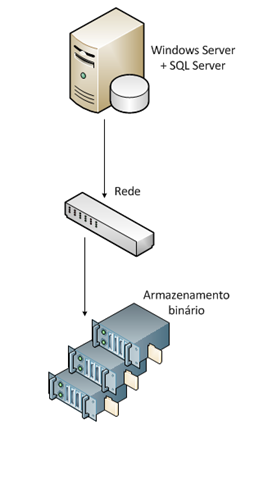
Antes de entrarmos no detalhamento das principais dúvidas, primeiramente precisamos de uma visão geral de como fica estruturada as máquinas no Azure ou AWS (figura 01). Em seguida mostro superficialmente a interface de gerenciamento das máquinas virtuais no Azure e a máquina criada.
Você vai criar uma máquina virtual no seu serviço da nuvem (os recursos de hardware variam de acordo com sua escolha) que conta com um ou mais discos locais, para receber o sistema operacional e outra área volátil (Azure), utilizada para o arquivo de paginação, por exemplo.
Depois o próximo passo é criar blocos em um armazenamento binário (tamanho à sua escolha: 30GB, 100GB, 150GB, etc.) que serão apresentados para a máquina, e com os discos presentes estes podem ser formatados e configurados da forma que desejar (básicos ou dinâmicos, RAID 1, RAID 5, etc.).
(Figura 01 – Modelo básico de arquitetura na nuvem)
O que é interessante para quem está começando com o IaaS é a simplicidade para criar essa estrutura, em 15 minutos você consegue subir uma máquina, criar os discos e acessar seu Windows através do terminal services. Mesmo você que não possui muito conhecimento de infra-estrutura, a configuração é muito fácil.
A figura 02 mostra a tela de gerenciamento de uma máquina virtual que eu criei no Azure ( confesso que achei muito bacana a interface nova do portal), lá temos uma visão geral da utilização dos recursos, nome e IP do host, discos (blobs) que foram apresentados para o SO, tipo da máquina (extra large) e onde está localizada. Depois disso foi só utilizar o disk management para criar meu RAID 5 controlado por software (figura 03).
(Figura 02 – Máquina no Azure)
(Figura 03 – Discos configurados)
A partir de agora você pode configurar o seu SQL Server e trabalhar com o seu workload para a nuvem! Agora se você vai ser feliz é outra história...
Perguntas e oportunidades
Se você chegou até aqui e achou que já ia encontrar todas as respostas, me desculpe! Ainda estamos fazendo muitos testes e validações de qual a melhor configuração e como podemos usar os recursos da nuvem sem risco para seu negócio, mas algumas perguntas que ouvimos são:
1. O subsistema de I/O consegue atender as minhas demandas?
2. Como devo configurar tempdb, dados e log na nuvem?
3. Colocando o SQL Server na nuvem não preciso de alta disponibilidade?
4. Colocando o SQL Server na nuvem não preciso de redundância ou backups?
5. Checagens de consistência ainda são necessárias ou o banco será incorruptível?
6. Consigo colocar minha aplicação deve ficar local acessando o SQL Server na nuvem?
7. Com o aumento de requisições o SQL Server vai fazer um scale-in automático?
Tentando responder algumas das perguntas, abaixo vou colocar outras ideias para uso da computação na nuvem, neste momento sob a ótica do IaaS.
· Nos testes preliminares de I/O parece que para uma boa quantidade de workloads sem grande estresse, a nuvem vai conseguir suportar a demanda.
· Distribuição dos arquivos e configuração de RAID (controlada por software) deve ser diferente. Dependendo da forma como os armazenamentos binários são tratados, um único arquivo grande (sem RAID) pode ser a melhor abordagem.
o É comum muitas empresas colocarem diferentes T-Logs em um único RAID 1 achando que estavam só com escrita sequencial. Não, sempre comento no Internals, o que vocês acabam por ter são escritas sequenciais randômicas.
o Com a nuvem é simples adicionar novos discos (blocos binários) e ter para cada um efetivamente a escrita sequencial.
· Os recursos são redundantes, o que não significa que você não pode ter downtime ou problemas operacionais, então sim, você ainda têm que pensar em alta disponibilidade e o mirroring (também o AlwaysOn) fica cada vez mais atrativo.
· Todo armazenamento dos blocos binários possuem redundância, então se onde um bloco está temos uma falha, outro bloco em algum lugar do datacenter assume. Porém antes dessa falha parar uma unidade, você pode ter uma operação de I/O problemática que corrompeu sua página de dados.
· Então backups ainda são necessários, checagens de consistência também. Agora se você tira o backup para um disco e ainda copia-o para outro local (ou utiliza o S3 da Amazon, por exemplo) você têm diversas redundâncias do arquivo de backup, e dependendo da configuração, até fora do datacenter (geográfica).
· A latência não é algo que pode ser desconsiderada, ainda mais com o datacenter fora do país, então para a maioria dos cenários é natural que sua aplicação vá para a nuvem junto com o banco.
· Para o IaaS não acontece o scale-in automático, mas é possível e simples, porém você deve se planejar para isso e fazer acontecer.
o Suponha que você tenha picos de utilização durante o ano, o que fazer com recurso on-premise? Você super dimensiona a máquina para suportar essas semanas.
o Um de nossos clientes têm 4 semanas de pico no ano, o que estamos planejando? Eles vão ficar 48 semanas rodando com uma instância menor (e mais barata) e antes das semanas pesadas vamos ter um pequeno downtime para desligar as máquinas, mudar o tipo de instância (dobrando os recursos de hardware) e subir o ambiente para atender o negócio. Limpo, mais barato e simples.
· Outras ideias que podemos utilizar recursos da nuvem...
o Escalabilidade horizontal: talvez não seja tão simples para banco de dados, mas para servidores web ou uma arquitetura de barramento, bem prático.
o Cache distribuído
o Ambientes de teste, homologação, reporting e hotfix: como nunca foi tão fácil alocar novas máquinas, ficou rotineiro separar os ambiente, começar a promover build automáticos, fazer testes de desempenho em ambiente paralelos, testar hotfixes, etc.
§ Um novo cliente quer testar seu software? Subo rápido uma imagem de máquina, aponto para alguns blocos de backup ou faço um restore do banco de dados e disponibilizo para teste enquanto for necessário (burocracia zero e custo baixo).
Encontrar a máquina com o balanceamento correto é sempre simples? Claro que não, hoje no Azure a maior VM têm 14GB de RAM, o que é muito pouco se eu colocar um SQL Server Standard que têm 64GB como limite (espero ver mudar logo isso, ainda estamos com preview). Já na Amazon nós temos VMs com 64GB de RAM e a licença do software é diluída no pagamento mensal, deixando a conta mais leve.
Paramos por aqui? Claro que não! Estamos listando uma série de outros detalhes e fazendo os testes necessários para garantir que o negócio funcione bem a um custo mais baixo. Em breve já vamos soltar um post comparando algumas configurações, throughput e tempo de resposta dos subsistemas de I/O, validando as diferenças entre Azure VMs e o EC2 da AWS (Amazon Web Services).
Revisando o post, achei que ele ficou com muitas ideias jogadas, mas como ele era quase um brainstorm do que estamos vendo e trabalhando com nossos clientes, espero que sirva para você pensar um pouco mais sobre cloud computing. E não, não acredito que 100% dos negócios vão para a nuvem, mas existe uma boa parcela que pode se beneficiar dessa economia de escala e facilidades oferecias.
Abraços,